嵌入
了解如何将文本转换为数字,解锁搜索等用例。
一览表
新的嵌入模型
text-embedding-3-small and text-embedding-3-large,
我们最新的、功能最强大的嵌入模型现在可用,具有较低的成本、更高的多语言性能和控制整体大小的新的参数。
什么是嵌入?
OpenAI 的文本嵌入可衡量文本字符串的相关性。嵌入通常用于:
- 搜索(其中结果按查询字符串的相关性排序)
- 聚类(其中根据相似性对文本字符串进行分组)
- 推荐(其中推荐具有相关文本字符串的项目)
- 异常检测(其中识别很少相关的离群值)
- 多样性测量(其中分析相似性分布)
- 分类(其中根据最相似的标签对文本字符串进行分类)
嵌入是一个浮点数向量(列表)。向量的距离衡量它们的相关性。较小的距离表明高度相关性,较大的距离表明低相关性。
访问我们的定价页面了解有关嵌入定价的更多信息。根据令牌在输入中的数量对请求进行计费。
如何获取嵌入
要获取嵌入,请将文本字符串发送到嵌入 API 端点,同时指定嵌入模型名称(例如 text-embedding-3-small)。响应将包含嵌入(浮点数列表),您可以提取它,将其保存在向量数据库中,并将其用于许多不同的用例:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'
响应将包含嵌入向量以及一些其他元数据。
默认情况下,嵌入向量的长度将为 1536 个 text-embedding-3-small 或 3072 个 text-embedding-3-large。您可以通过传递维度参数来减少嵌入的维度,而不会丢失其概念表示属性。我们将在嵌入用例部分中更详细地介绍嵌入维度。
模型
嵌入模型
OpenAI 提供了两个功能强大的第三代嵌入模型(用 -3 表示模型 ID)。您可以在嵌入 v3 公告博客文章中了解更多详细信息。
使用情况的定价如下,其中页面数是根据每页约 800 个令牌计算的:
| 模型 | 每美元页面数 | MTEB 评估上的性能 | 最大输入 |
|---|---|---|---|
| text-embedding-3-small | 62,500 | 62.3% | 8191 |
| text-embedding-3-large | 9,615 | 64.6% | 8191 |
| text-embedding-ada-002 | 12,500 | 61.0% | 8191 |
用例
以下是一些代表性用例。我们将使用 Amazon 精细食品评论数据集进行以下示例。
获取嵌入
该数据集包含 568,454 条食品评论,这些评论是亚马逊用户在 2012 年 10 月之前留下的。我们将使用最近 1,000 条评论的子集进行说明。评论以英语撰写,通常是正面的或负面的。每个评论都有一个 ProductId、UserId、评分、评论标题(摘要)和评论正文(文本)。例如:
| Product Id | User Id | 评分 | 摘要 | 文本 |
|---|---|---|---|---|
| B001E4KFG0 | A3SGXH7AUHU8GW | 5 | 优质狗粮 | 我买了几种 Vitality 罐装... |
| B00813GRG4 | A1D87F6ZCVE5NK | 1 | 广告不实 | 产品标签为 Jumbo Salted Peanut... |
我们将将评论摘要和评论正文合并为单个组合文本。模型将对该组合文本进行编码并输出单个向量嵌入。
from openai import OpenAI
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-3-small'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)
要从保存的文件中加载数据,您可以运行以下内容:
import pandas as pd
df = pd.read_csv('output/embedded_1k_reviews.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array)
减少嵌入维度
使用较大的嵌入,例如将它们存储在向量存储中以进行检索,通常比使用较小的嵌入成本更高,并且消耗更多的计算、内存和存储。
我们的第三代嵌入模型(用 -3 表示)训练可以动态调整大小,这允许开发人员在不丢失概念表示属性的情况下缩短嵌入。具体来说,开发人员可以通过传递维度 API 参数来缩短嵌入,从而权衡性能和成本。例如,在 MTEB 基准上,text-embedding-3-large 嵌入的大小可以缩短到 256,同时仍优于未缩短的 text-embedding-ada-002 嵌入,其大小为 1536。您可以在我们的嵌入 v3 发布博客文章中了解有关更改维度如何影响性能的更多详细信息。
一般来说,使用 dimensions 参数来创建嵌入是建议的方法。在某些情况下,您可能需要在创建嵌入后手动更改嵌入维度。当您手动更改维度时,您需要确保规范化维度,如下所示。
from openai import OpenAI
import numpy as np
client = OpenAI()
def normalize_l2(x):
x = np.array(x)
if x.ndim == 1:
norm = np.linalg.norm(x)
if norm == 0:
return x
return x / norm
else:
norm = np.linalg.norm(x, 2, axis=1, keepdims=True)
return np.where(norm == 0, x, x / norm)
response = client.embeddings.create(
model="text-embedding-3-small",
input="Testing 123",
encoding_format="float"
)
cut_dim = response.data[0].embedding[:256]
norm_dim = normalize_l2(cut_dim)
print(norm_dim)
动态更改维度使使用非常灵活。例如,当使用仅支持最大 1024 维度嵌入的向量数据存储时,开发人员现在仍然可以使用我们最好的嵌入模型 text-embedding-3-large,并指定值为 1024 的 dimensions API 参数,这将缩短嵌入大小,同时牺牲一些准确性来换取较小的向量大小。
使用嵌入进行问答
有许多常见情况,模型并未在包含关键事实和信息的数据上进行训练,而这些信息对于生成对用户查询的响应非常重要。一种解决此问题的方法(如下所示)是将其他信息放入模型的上下文窗口中。这种方法有效,但在某些情况下会导致更高的令牌成本。在本笔记本中,我们将探索这种方法与基于嵌入的搜索之间的权衡。
query = f"""Use the below article on the 2022 Winter Olympics to answer the subsequent question. If the answer cannot be found, write "I don't know."
Article:
\"\"\"
{wikipedia_article_on_curling}
\"\"\"
Question: Which athletes won the gold medal in curling at the 2022 Winter Olympics?"""
response = client.chat.completions.create(
messages=[
{'role': 'system', 'content': 'You answer questions about the 2022 Winter Olympics.'},
{'role': 'user', 'content': query},
],
model=GPT_MODEL,
temperature=0,
)
print(response.choices[0].message.content)
使用嵌入进行文本搜索
要检索最相关的文档,我们使用嵌入向量之间的余弦相似度,并返回最高得分的文档。
from openai.embeddings_utils import get_embedding, cosine_similarity
def search_reviews(df, product_description, n=3, pprint=True):
embedding = get_embedding(product_description, model='text-embedding-3-small')
df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_reviews(df, 'delicious beans', n=3)
使用嵌入进行代码搜索
代码搜索与基于嵌入的文本搜索类似。我们提供了一种方法来从所有 Python 文件中提取 Python 函数。然后,我们使用 text-embedding-3-small 模型对每个函数进行索引。
要执行代码搜索,我们使用与代码查询相同的模型对查询进行嵌入。然后,我们计算查询嵌入与每个函数嵌入之间的余弦相似度。最相似的余弦相似度结果是最相关的。
from openai.embeddings_utils import get_embedding, cosine_similarity
df['code_embedding'] = df['code'].apply(lambda x: get_embedding(x, model='text-embedding-3-small'))
def search_functions(df, code_query, n=3, pprint=True, n_lines=7):
embedding = get_embedding(code_query, model='text-embedding-3-small')
df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_functions(df, 'Completions API tests', n=3)
使用嵌入进行推荐
由于较短的距离表示嵌入向量之间的更高相似性,因此嵌入可用于推荐。
下面,我们演示了一个基本的推荐程序。它采用一组字符串和一个“源”字符串的索引,计算它们的嵌入,然后返回排序的字符串,按从最相似到最不相似排序。作为具体的示例,下面的笔记本将此功能应用于 AG 新闻数据集(采样为 2,000 篇新闻文章描述),以返回与任何给定源文章最相似的 5 篇文章。
from openai.embeddings_utils import get_embedding, cosine_similarity
def recommendations_from_strings(
strings: List[str],
index_of_source_string: int,
model="text-embedding-3-small",
) -> List[int]:
"""Return nearest neighbors of a given string."""
embeddings = [embedding_from_string(string, model=model) for string in strings]
# get the embedding of the source string
query_embedding = embeddings[index_of_source_string]
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
# get indices of nearest neighbors (function from embeddings_utils.py)
indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)
return indices_of_nearest_neighbors
使用嵌入进行数据可视化
嵌入的大小因底层模型的复杂性而异。为了可视化这些高维数据,我们使用 t-SNE 算法将数据转换为二维数据。
我们根据评论者给出的星级对评论进行着色:
- 1 星:红色
- 2 星:深橙色
- 3 星:金色
- 4 星:青绿色
- 5 星:深绿色
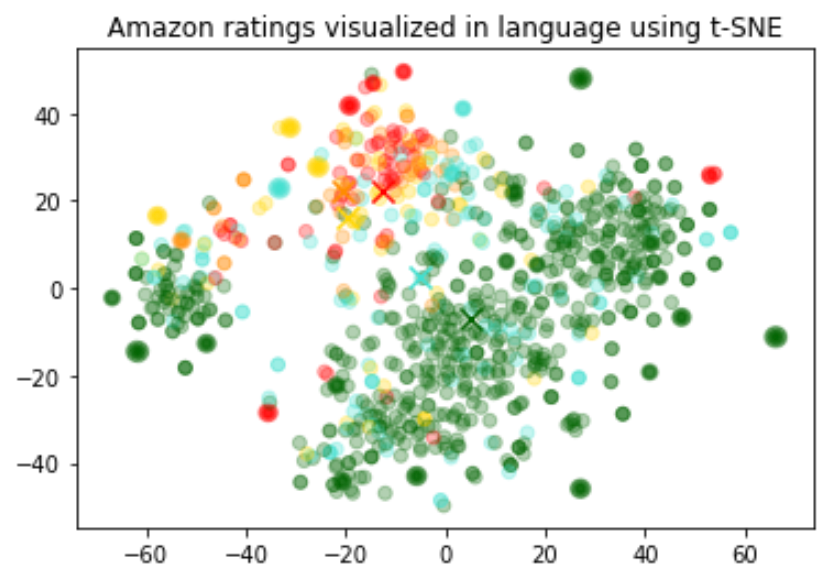
可视化似乎产生了大约 3 个聚类,其中一个聚类中主要是负面评论。
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlib
df = pd.read_csv('output/embedded_1k_reviews.csv')
matrix = df.ada_embedding.apply(eval).to_list()
# Create a t-SNE model and transform the data
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
colors = ["red", "darkorange", "gold", "turquiose", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
plt.title("Amazon ratings visualized in language using t-SNE")
使用嵌入功能进行回归
嵌入可用作机器学习算法中的通用自由文本特征编码器。将嵌入纳入机器学习模型可以改善任何机器学习模型的性能,前提是某些相关输入是自由文本。嵌入还可用作机器学习算法中的分类特征编码器。如果类别名称具有意义且数量众多(例如工作头衔),则这种方法会增加最大的价值。与搜索嵌入相比,相似性嵌入通常在这种任务中表现更好。
我们观察到,由于嵌入表示的信息非常丰富,因此,即使将输入维度减少 10%,也会降低下游特定任务的性能。
此代码将数据分为训练集和测试集,这两个用例(即回归和分类)将使用该数据。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
list(df.ada_embedding.values),
df.Score,
test_size = 0.2,
random_state=42
)
使用嵌入功能进行回归
嵌入以优雅的方式预测数值。在本例中,我们根据评论的文本预测评论者的星级评分。因为嵌入包含的语义信息很多,即使评论很少,预测也相当不错。
我们假设评分是 1 到 5 之间的连续变量,并允许算法预测任何浮点值。 ML 算法最小化预测值与真实评分之间的距离,并实现 0.39 的平均绝对误差,这意味着预测平均误差不到半颗星。
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)
Zero-shot 分类
我们可以使用嵌入进行 Zero-shot 分类,而无需任何标记的训练数据。对于每个类别,我们嵌入类别名称或类别的简短描述。要对一些新文本进行 Zero-shot 分类,我们将其嵌入与所有类嵌入进行比较,并预测具有最高相似性的类别。
from openai.embeddings_utils import cosine_similarity, get_embedding
df= df[df.Score!=3]
df['sentiment'] = df.Score.replace({1:'negative', 2:'negative', 4:'positive', 5:'positive'})
labels = ['negative', 'positive']
label_embeddings = [get_embedding(label, model=model) for label in labels]
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
prediction = 'positive' if label_score('Sample Review', label_embeddings) > 0 else 'negative'
获取用户和产品嵌入以进行冷启动推荐
我们可以通过平均所有评论来获得用户嵌入。类似地,我们可以通过平均所有有关该产品的评论来获得产品嵌入。为了展示该方法的有用性,我们使用了 50k 条评论的子集,以覆盖更多的用户和产品评论。
我们在单独的测试集上评估这些嵌入的有用性,其中我们将用户和产品嵌入的相似性作为评分的函数。有趣的是,根据这种方法,在用户接收到产品之前,我们可以比随机更好地预测用户是否会喜欢该产品。
user_embeddings = df.groupby('UserId').ada_embedding.apply(np.mean)
prod_embeddings = df.groupby('ProductId').ada_embedding.apply(np.mean)
聚类
聚类是理解大量文本数据的一种方式。嵌入在这个任务中很有用,因为它们提供了每个文本的语义上有意义的向量表示。因此,在无监督的情况下,聚类将揭示我们数据集中的隐藏分组。
在本示例中,我们发现了四个不同的聚类:一个聚集在狗粮上,一个聚集在负面评论上,以及两个聚集在正面评论上。
import numpy as np
from sklearn.cluster import KMeans
matrix = np.vstack(df.ada_embedding.values)
n_clusters = 4
kmeans = KMeans(n_clusters = n_clusters, init='k-means++', random_state=42)
kmeans.fit(matrix)
df['Cluster'] = kmeans.labels_
常见问题解答
在将文本嵌入到模型中之前,如何知道它有多少个令牌?
您可以使用 OpenAI 的令牌器 tokenizer tiktoken 在 Python 中将字符串分割为令牌。
示例代码:
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")
对于第三代嵌入模型(如 text-embedding-3-small),请使用 cl100k_base 编码。
有关更多详细信息和示例代码,请参阅 OpenAI Cookbook 指南《如何使用 tiktoken 计算令牌数》。
如何快速检索 K 个最近的嵌入向量?
对于在许多向量中快速搜索的情况,我们建议使用向量数据库。您可以在我们的 GitHub 上的 Cookbook 中找到使用向量数据库和 OpenAI API 的示例。
哪个距离函数应该使用?
我们建议使用余弦相似性。距离函数的选择通常对结果的影响不是很大。
OpenAI 嵌入是归一化为长度 1 的,这意味着:
- 余弦相似性可以使用点积 légèrement plus rapide 计算
- 余弦相似性和欧几里德距离将产生相同的排名
我能在网上分享我的嵌入吗?
是的,客户拥有其输入和输出的所有权,包括在嵌入的情况下。您有责任确保您输入到我们的 API 的内容不违反任何适用的法律或我们的《使用条款》。
V3 嵌入模型了解最近的事件吗?
否,text-embedding-3-large 和 text-embedding-3-small 模型缺乏 2021 年 9 月之后发生的事件的知识。这对于嵌入模型通常不是一个限制,但在某些边缘情况下可能会降低性能。