如何使用助理 API
助理 API旨在帮助开发者构建强大的AI助手,能够执行各种任务。
- 助理可以调用OpenAI的模型,并提供具体的指示来调整其性格和能力。
- 助理可以并行访问多个工具。这些工具可以是OpenAI托管的工具,如
code_interpreter和file_search,也可以是您自己构建或托管的工具(通过函数调用)。 - 助理可以访问持久化的线程。线程简化了AI应用程序的开发,方法是存储消息历史并在对话过于长而超出模型上下文长度时进行截断。您可以创建一个线程,然后简单地向其追加消息。
- 助理可以访问多种格式的文件。在使用工具时,助理还可以创建文件(如图像、电子表格等),并在创建的消息中引用它们所引用的文件。
对象
助理 API的体系结构如下所示:
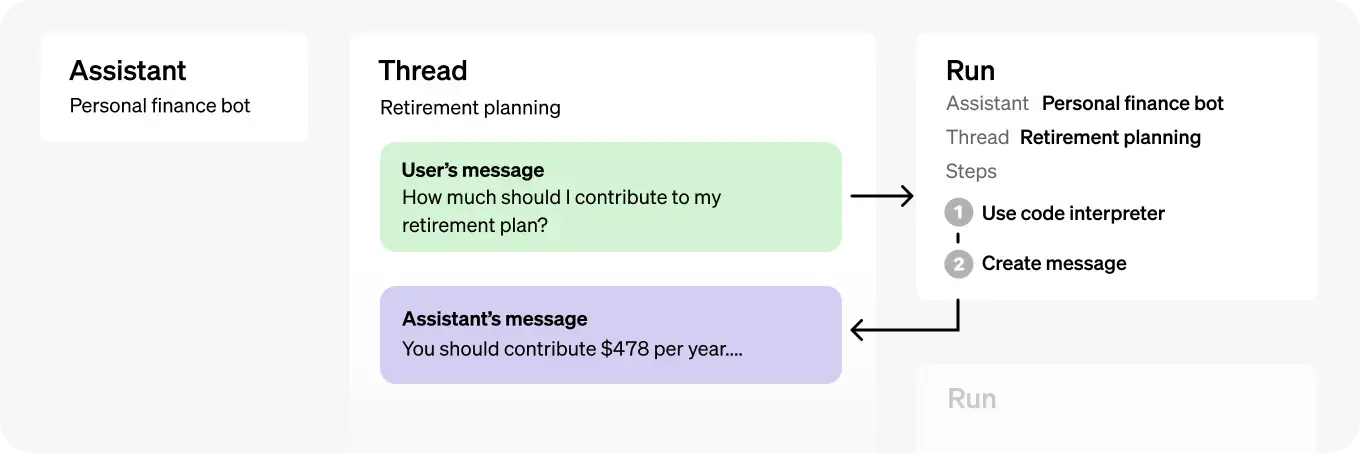
以下是助理 API中使用的对象及其功能:
| 对象 | 描述 |
|---|---|
| 助理 | 专门为执行特定任务而构建的AI,它使用OpenAI的模型并调用工具 |
| Thread | 在助理和用户之间的会话会话。线程存储消息并自动处理截断,以便将内容适应于模型的上下文。 |
| Message | 由助理或用户创建的消息。消息可以包含文本、图像和其他文件。消息存储为Thread上的消息列表。 |
| Run | 助理在Thread上的调用。助理使用其配置和Thread的消息来执行任务,方法是调用模型和工具。在进行Run时,助理向Thread追加消息。 |
| Run Step | 在进行Run时,助理执行的详细步骤。通过检查Run步骤,您可以了解助理如何获得其最终结果。 |
创建助理
要创建助理,只需指定要使用的model即可。但是,您还可以进一步自定义助理的行为:
- 使用
instructions参数来指导助理的性格和目标。这些说明类似于聊天完成 API中的系统消息。 - 使用
tools参数为Assistant提供对最多128个工具的访问权限。您可以授予其访问OpenAI托管的工具(如code_interpreter和file_search),或者通过函数调用调用第三方工具。 - 使用
tool_resources参数为code_interpreter和file_search等工具提供对文件的访问权限。文件使用File API的create端点上传,并且必须将purpose设置为assistants以便与此API一起使用。
例如,要创建一个能够根据.csv文件创建数据可视化的助理,首先需要上传一个文件。
file = client.files.create(
file=open("revenue-forecast.csv", "rb"),
purpose='assistants'
)
然后,创建具有code_interpreter工具的助手,并将文件提供给工具作为资源。
assistant = client.beta.assistants.create(
name="Data visualizer",
description="You are great at creating beautiful data visualizations. You analyze data present in .csv files, understand trends, and come up with data visualizations relevant to those trends. You also share a brief text summary of the trends observed.",
model="gpt-4o",
tools=[{"type": "code_interpreter"}],
tool_resources={
"code_interpreter": {
"file_ids": [file.id]
}
}
)
您可以将最多20个文件附加到code_interpreter,并将10,000个文件附加到file_search(使用vector_store对象)。
每个文件最多可以为512 MB,最多为5,000,000个令牌。默认情况下,组织的所有文件的大小不能超过100 GB,但是您可以联系我们的支持团队以增加此限制。
管理线程和消息
线程和消息表示助理和用户之间的会话会话。没有消息数量的限制。一旦消息的大小超过了模型的上下文窗口,线程将尝试智能地截断消息,然后完全删除最不重要的消息。
您可以使用初始消息列表创建线程,如下所示:
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": "Create 3 data visualizations based on the trends in this file."
}
]
)
消息可以包含文本、图像或文件附件。消息附件attachments是帮助方法,用于将文件添加到线程的tool_resources中。您还可以选择将文件直接添加到thread.tool_resources中。
创建图像输入内容
消息内容可以包含外部图像URL或使用File API上传的文件ID。但是,只有支持视觉功能的模型才能接受图像输入。支持的图像内容类型包括png、jpg、gif和webp。当创建图像文件时,请将purpose设置为vision,以便您以后可以下载和显示输入内容。目前,每个组织的限制为100GB,每个组织用户的限制为10GB。请联系我们以请求增加限制。
工具无法访问图像内容,除非您在消息的attachments列表中指定文件ID。图像URL无法在Code Interpreter中下载。
低或高保真度的图像理解
通过控制detail参数,您可以控制模型如何处理图像并生成其文本理解。该参数有三个选项:low,high或auto。
low将启用“低分辨率”模式。模型将接收到512px x 512px的低分辨率图像版本,并用85个令牌表示图像。这使API能够更快地返回响应并消耗更少的输入令牌,适用于不需要高分辨率的情况。high将启用“高分辨率”模式,该模式首先允许模型查看低分辨率图像,然后根据输入图像的大小创建详细的图像裁剪。使用定价计算器查看不同图像大小的令牌计数。
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the difference between these images?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "image_file",
"image_file": (
"file_id": file.id
)
},
],
}
]
)
上下文窗口管理
助手 API会自动管理截断,以确保其保持在模型的最大上下文长度。您可以通过指定要在单个运行中利用的最大令牌数和/或要在运行中包含的最近消息数来自定义此行为。
例如,使用max_prompt_tokens设置为500和max_completion_tokens设置为1000进行初始运行,意味着第一个完成将截断线程为500个令牌,并将输出限制为1000个令牌。如果仅使用了200个提示令牌和300个完成令牌,那么第二个完成将有可用的限制为300个提示令牌和700个完成令牌。
如果完成达到max_completion_tokens限制,则运行将以状态incomplete终止,并在incomplete_details字段的运行对象中提供详细信息。
当使用文件搜索工具时,我们建议将max_prompt_tokens设置为不少于20,000。对于更长的对话或多次与文件搜索的交互,请考虑将此限制增加到50,000,或者最好是完全删除max_prompt_tokens限制,以获得最高质量的结果。
您还可以指定截断策略,以控制如何将线程呈现到模型的上下文窗口中。使用类型为auto的截断策略将使用OpenAI的默认截断策略。使用类型为last_messages的截断策略将允许您指定要在上下文窗口中包含的最近消息的数量。
消息注释
助理创建的消息可能包含annotations在content数组的对象中。注释提供有关如何注释文本的信息在消息中。
有两种类型的注释:
file_citation:文件引用是由file_search工具创建的,它们定义对特定已上传并由助理用于生成响应的文件的引用。file_path:文件路径注释是由code_interpreter工具创建的,它们包含对生成的文件的引用。
当注释存在在消息对象中时,您会在文本中看到模型生成的不可读的子字符串,您应该用注释来替换这些子字符串。这些字符串可能看起来像【13†source】或sandbox:/mnt/data/file.csv。以下是一个Python代码片段,它用信息替换了注释中的字符串。
# Retrieve the message object
message = client.beta.threads.messages.retrieve(
thread_id="...",
message_id="..."
)
# Extract the message content
message_content = message.content[0].text
annotations = message_content.annotations
citations = []
# Iterate over the annotations and add footnotes
for index, annotation in enumerate(annotations):
# Replace the text with a footnote
message_content.value = message_content.value.replace(annotation.text, f' [#{index}]')
# Gather citations based on annotation attributes
if (file_citation := getattr(annotation, 'file_citation', None)):
cited_file = client.files.retrieve(file_citation.file_id)
citations.append(f'[#{index}] {file_citation.quote} from {cited_file.filename}')
elif (file_path := getattr(annotation, 'file_path', None)):
cited_file = client.files.retrieve(file_path.file_id)
citations.append(f'[#{index}] Click <here> to download {cited_file.filename}')
# Note: File download functionality not implemented above for brevity
# Add footnotes to the end of the message before displaying to user
message_content.value += '\n' + '\n'.join(citations)
运行和运行步骤
当您在线程中有所有所需的上下文时,您可以使用所选的助理运行线程。
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
默认情况下,运行将使用model和tools配置指定在助理对象中,但是您可以在创建运行时进行灵活的重写:
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
model="gpt-4o",
instructions="New instructions that override the Assistant instructions",
tools=[{"type": "code_interpreter"}, {"type": "file_search"}]
)
注意:tool_resources与助理关联的不能在运行期间进行重写。您必须使用modify Assistant端点来进行此操作。
运行生命周期
运行对象可以具有多种状态。
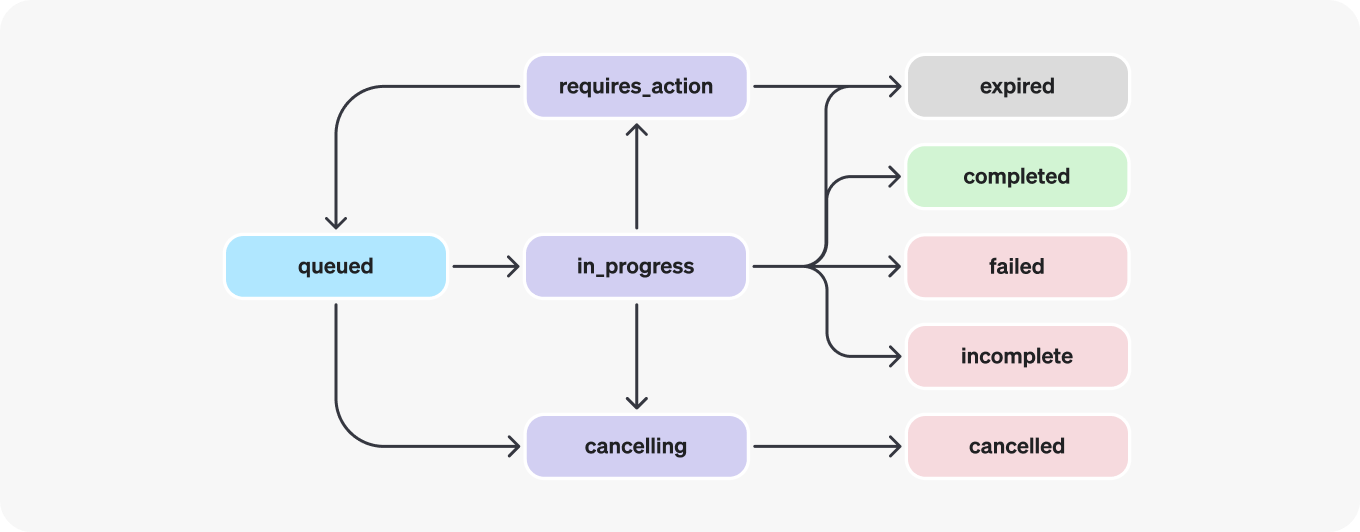
| 状态 | 定义 |
|---|---|
queued | 当运行首次创建或者您完成了required_action时,它们将被移动到排队状态。它们应该几乎立即进入到in_progress状态。 |
in_progress | 在in_progress状态下,Assistant使用模型和工具执行步骤。您可以通过查看运行步骤来查看进展情况。 |
completed | 运行成功完成!您现在可以查看Assistant向线程添加的所有消息,并查看运行所执行的所有步骤。您还可以通过向线程添加更多用户消息并创建另一个运行来继续对话。 |
requires_action | 当使用函数调用工具时,运行将移动到required_action状态,一旦模型确定了要调用的函数的名称和参数。您必须运行这些函数并提交输出,然后运行才能继续。如果未在expires_at时间戳之前(大约为创建时间之后的10分钟)提交输出,则运行将进入到过期状态。 |
expired | 当函数调用输出未在expires_at之前提交,或者运行花费的时间超过了expires_at所指定的时间,我们的系统将使运行过期。 |
cancelling | 您可以尝试使用取消运行端点来取消处于in_progress状态的运行。一旦取消尝试成功,运行的状态将变为cancelled。取消是尝试的,但并不保证。 |
cancelled | 运行已成功取消。 |
failed | 您可以通过查看运行中的last_error对象来了解失败的原因。失败的时间戳将记录在failed_at中。 |
incomplete | 运行由于达到max_prompt_tokens或max_completion_tokens而结束。您可以通过查看运行中的incomplete_details对象来了解具体原因。 |
轮询更新
如果您没有使用流式处理,为了使运行的状态保持最新,您需要定期检索运行对象。您可以在每次检索对象时检查运行的状态,以了解应用程序应该执行的操作。
您可以选择使用Node和Python SDK中的轮询助手来帮助您进行此操作。这些助手将自动为您轮询运行对象,并在其进入终止状态时返回运行对象。
线程锁
当运行处于in_progress状态且未处于终止状态时,线程将被锁定。这意味着:
- 无法向线程添加新消息。
- 无法在线程上创建新运行。
数据访问指导
目前,助手、线程、消息和矢量存储是通过API创建的,并且作用域为项目。因此,项目中具有API键访问权限的任何人都可以读取或写入项目中的助理、线程、消息和运行。
我们强烈建议实施以下数据访问控制:
- 实施授权。在执行对助理、线程、消息和矢量存储的读/写操作之前,请确保端用户具有执行此操作的授权。例如,在您的数据库中存储端用户可访问的对象ID,并在使用API检索对象ID之前进行检查。
- 限制API键访问权限。仔细考虑谁应该在项目中拥有API键,并定期审核此列表。API键可以执行各种操作,包括读取和修改敏感信息,如消息和文件。
- 创建单独的帐户。考虑为不同的应用程序创建单独的项目,以隔离跨多个应用程序的数据。
下一步是什么
现在您已经了解了助理的工作原理,下一步是探索助手工具,其中涉及的主题包括函数调用、文件搜索和代码解释器。